
This is an implementation of an Artificial Intelligence fully written in Javascript that learns to play the game Snake using Reinforcement Learning.
The AI learns to play the game during its training process (every time it catches a fruit or dies). Therefore, the longer you let it train, the better it gets!
Play with it…
-
Learning Rate: How aggressive the AI will learn to play (close to 0 will be too slow, while close to 1 will simply replace the old learned value with the new one). Higher is not necessarily better
-
Discount Factor: Importance between immediate rewards and future rewards
-
Action Randomization: Percentage of time a random action will be executed instead of the desired action
You can check the GitHub Repository to see the source code of this project. If you like it, give it a star!
If you want to play some snake yourself, you should try clicking the canvas and entering the Konami Code! See what happens…
How it works
The first question I was asked when I came up with this idea: “Why do you want to use Javascript instead of Python?”. I know Python has some libraries for scientific computing (like NumPy and TensorFlow), but I wanted something that worked right out of the box: no installation, running directly in the browser. This way, anyone can test and play with it without worrying about setting up a proper environment.
Snake (the game itself)
Snake is a game in which a snake needs to explore an environment and catch the fruit without hitting any obstacle or itself. Every time the snake catches a fruit, its size increases.
I could have forked another Snake repository, but since I didn’t know Javascript (and I would need to use it on the next steps), I thought that developing the Snake game from scratch would be a good idea to learn more about it.
To develop this part of the project, I used these contents for guidance:
- Coding “Snake” in 4 min 30 sec
- Mastering the Module Pattern (not really about Snake itself, but a pattern I tried to follow on the project)
See game.js for the source code.
Q-Learning
Accordingly to Christopher Watkins, “Q-Learning is a simple way for agents to learn how to act optimally in controlled Markovian domains” (Watkins, 1989). In simple terms, it uses a MDP (Markov Decision Process) to control and make decisions in an environment. It consists of a Q-Table that is constantly updated.
A Q-Table is a matrix with a set of states and respective action’s probability of success. When the agent explore the environment, the table is updated. The action with the biggest value is considered the best action to make.
In this guide I will explain how I applied Q-Learning in the Snake game. If you want to understand more deeply (yet in a simple way) about Q-Learning and Reinforcement Learning, I suggest this Medium post by Vishal Maini.
See q-learning.js for the source code.
Algorithm
The algorithm consists of:
| s = game.state() | get state s |
| act = best-action( Q(s) ) | execute best action act given state s |
| rew = game.reward( ) | receive reward rew |
| s’ = game.state() | get next state s’ |
| Q(s, act) = update-qTable( ) | update Q-Table value q of state s and action act |
Update Q-Table
The new Q-Table value for the action accomplished is given by this formula (taken from the article by Vishal Maini):

It’s executed after the action is taken and the reward is known.
Actions
Available actions are “UP”, “DOWN”, “LEFT” and “RIGHT”, simulating a user interaction with the game.
| UP | DOWN | LEFT | RIGHT |
The best action is selected by choosing the biggest action value in a certain state in the Q-Table. If the maximum value equals 0, a random action is selected.
Reward
The only reward is given when the snake grabs the fruit ( +1 ). I tried also giving a small reward (approximately +0.1) when it successfully explored the environment without dying, but the result was that the snake only moved on the environment in circles without really caring about the fruit.
The penalty happens whenever the game resets ( -1 ), that is, the snake hits its tail or a wall.
If anything else happens, there’s a minor negative reward ( -0.1 ). That’s ideal to minimize the path taken to catch the fruit and makes the training process faster.
| Action | Reward |
|---|---|
| Catch the Fruit | + 1 |
| Hits tail | - 1 |
| Hits wall | - 1 |
| Else | - 0.1 |
States
First I tried creating a dictionary of states based on all the snake positions and trail formats. Although it worked, as a result of the high number of states, it was necessary to let the code train for a very long time. Since this project was intended to give a fast explanation and to show a fast result to the user (and the results are not saved across sessions), this way to save states in the dictionary was not the best approach.
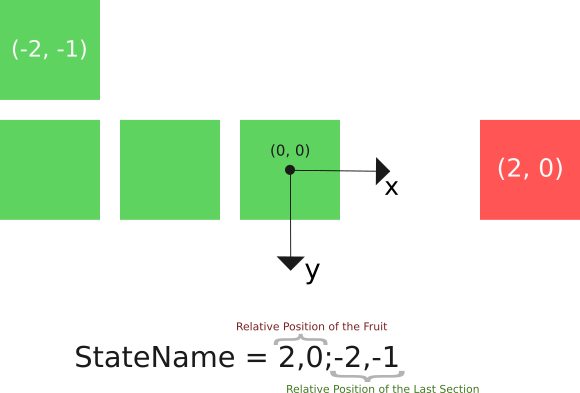
To work around this limitation, the dictionary of states is based only in the relative position of the fruit to the head of the snake and the relative position of the last tail section to the head of the snake.
In this way, the dictionary of states stores the name like this:
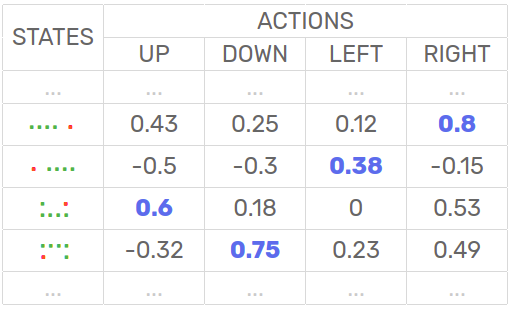
The Q-Table is stored using a Javascript Object and looks like this:

If you want to test this algorithm with a full set of states, you can clone the project on GitHub and change a few lines to see how it behaves.
If you liked this project, please give it a star on GitHub to show your appreciation!
Interesting Links
-
Q-Learning-Python-Example by Hasan Iqbal: an implementation of Q-Learning for the game “Catch the Ball”, which I used to understand the algorithm steps.
-
IAMDinosaur by Ivan Seidel: Artificial Inteligence that teachs Google’s Dinosaur to jump cactus. Not directly related to this project, but an awesome idea!